
Performance and cost control are at the center of every business owner’s to-do list. Companies are under pressure to deliver highly responsive IT services. Cloud computing was once praised as the absolute solution for better IT services and budget savings, but more businesses are losing faith in it as it has shown its limitations. The reason is, computing now involve the usage of more smart devices and it is clear that the cloud’s centralized model is a bottleneck to performance. Fortunately, there are some alternatives to cloud computing and one of them is “fog computing”.
But what is “fog computing”? In this article, we’ll take a look at its basics, explain how it relates to the Internet of Things (IoT) and show how it can help you generate income.
Defining Fog Computing – How Is It Related to IoT?
The term “fog computing” appeared in 2012 when scientists started outlining the need for consistent performance in IoT scenarios that requires computing “at the edge” of the network.
Fog computing is the practice of extending cloud computing to the edge of the network, using computers and servers that are more powerful than traditional “edge devices”. In this way, it’s related to edge computing – but it’s still a distinct concept.
Think of it this way. In a traditional edge computing scenario, such as monitoring temperature in a plant, data may be collected and processed directly by advanced temperature sensors, before it’s sent to a cloud server. In this case, 10% of computing power may be located in the edge devices – but about 90% of the work is still done in the central cloud.
As the name suggests, “fog computing” expands the cloud at a much greater scale. Let’s use self-driving cars as an example. Together, the computers in the car and the local edge devices used to process this data could do 50% or more of the computing. The central cloud data center may be responsible for less than 50% of the total workload.
Essentially, then, fog computing is a decentralized method of computing, that focuses on using multiple, smaller data centers (“cloudlets”) located in different geographical areas, which handle a larger percentage of the workload, compared to a traditional edge computing installations.

Scenarios For Fog Computing – What Is It Used For?
Fog computing is ideal for scenarios in which efficiency and low latency are critical, and where it’s necessary to reduce the amount of data that is sent to the primary cloud data center for analysis, processing, and storage.
Here are a few examples of scenarios for fog computing, based on information released by Cisco and papers published by Hindawi and AI Trends.
- Autonomous vehicles – We already touched upon how fog computing can be used for self-driving cars. Compared to edge computing, fog computing allows for faster data processing, because more work is done outside of central data centers, and vehicles can “learn” more quickly.
- Connected “smart cities” – Fog computing architecture may be increasingly utilized to create “smart cities”, and monitor things like utility consumption, transit, water consumption and quality, and other such basic metrics of public health and quality of life.
It allows all of this data to be interpreted at the source for faster responses, and then aggregated into a central database. And because useless or irrelevant data can be discarded in real-time, it’s easier for city officials to get insights into what can be done better in the city. - Better real-time analytics – Fog computing can be used in hundreds of different ways for better real-time analytics. Let’s take manufacturing, for example. Fog computing can be used to quickly assess quality of products and to gain other such insights at each manufacturing plant. Then, this data is distributed into a larger data center, in order to gather insights about the performance of each individual facility, and compare them.
Because data “fogging” improves efficiency even further than edge computing, it’s an ideal choice for any application where real-time data interpretation is critical.
Fog Computing and Edge Computing Have a Lot in Common
Fog computing is commonly mistaken with edge computing in general. You can now clearly understand that whenever an edge computing scenario involves cloudlets, it is actually fog computing.
So, in common language, ‘”fog computing” is referred to as “edge computing”. One of the reasons is they share the same advantages and disadvantages.
Pros
The primary advantage of fog computing is that it will lower response and data interpretation times for your applications. This happens because more processing power is made available in the same geographic locations as the data collection points.
Another advantage is that the pre-processed data is usually encrypted prior to being transported to cloud data centers. This adds another level of security and makes your applications safer.
Cons
The disadvantage of fog computing is increased complexity. Deploying “cloudlets” in more locations requires to be able to manage a larger infrastructure. Consequently, this could incur more costs when deployments and operations are not automated.

Generating Revenue with Fog Computing: The Content Delivery Network Case
Fog computing is a great opportunity for local service providers to offer a ready-to-use, small-scale infrastructure that will generate substantial income.
Let’s take an example. We recently launched our new website. In the objective to enhance the user experience and reduce the page loading time on our website, we chose to use a Content Delivery Network (CDN). A CDN is a geographically distributed network of proxy servers and data centers. Its goal is to distribute web content with high availability and performance.
When looking at the statistics on the page loading time before and after we started using a CDN, we noticed the loading page time was still extremely high for users in a few countries. With further investigation, we’ve been able to point out there are no proxy nodes currently in the CDN for these specific countries. Consequently, when users browse pages, these are fetched directly from the initial server’s cache, not a local copy. Add this to low local network speeds and you end up with increased latency and poor user experience.
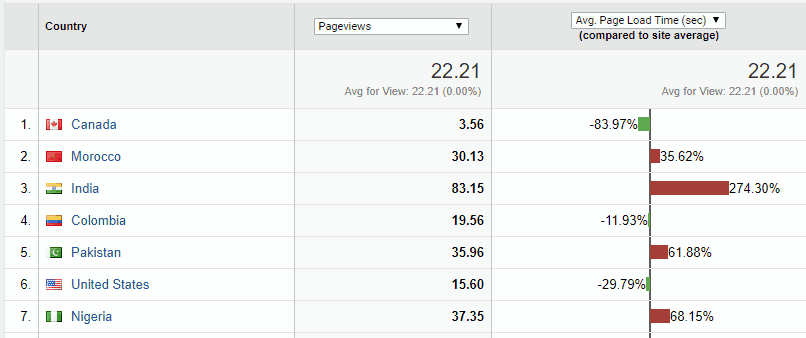
Delivering CDN servers in your country or region can turn into a revenue-generating business. The demand for better web services is global and you can make money on offering ready-to-use infrastructure for thousands of businesses out there.
Ormuco Edge can help you achieve this. Our solution is versatile and extremely scalable. It can be run on consumer-grade equipment, which enables affordable fog computing.
And, for larger-scale applications, Ormuco software can be deployed on both private servers and data centers, allowing it to be used for more advanced, resource-intensive projects and deployments.
With support for bare metal hardware, as well as containers like Kubernetes, and a flexible structure that allows for the easy importation of almost all cloud-based software and infrastructure, Ormuco Edge is the ideal platform for any company interested in experimenting with fog or edge computing.



